
A little over a year ago, we introduced F1, our in-house transaction categorisation engine, designed to make sense of complex banking data. Today, we're excited to share significant advancements in F1.
Intelligent tagging
We're rolling out an early version of F1 through Beta Playground. It's been in development and testing for the past few months.

Auto-tagging (automatically adding metadata – tag, icon, merchant) transactions plays a crucial part in managing finances. The standard way to handle this is to allow users to set some sets of rules or patterns. This approach puts the onus of automation on the end user, when in 2023 systems should be sufficiently advanced to tackle this themselves. This is what F1 does.
Auto-Tagging Future transactions
F1 now intelligently learns from your tagging preferences. By adding new tags or editing existing ones, you can help train the underlying model to understand your preferences. If you'd like to change the default for "Ramesh Tea Stall" from "Ramesh" to "Chai Shop," that's okay with us. Your visits from now on will all be noted as "Chai Shop."
How have we reached here?
It was evident from the beginning that automating categorisation is going to play a huge role in Fold’s adoption.
As we started building this, we encountered numerous engineering challenges. Our initial approach with a rule-based approach soon revealed its limitations in accuracy, particularly due to the lack of standardization in transaction descriptions.
This realisation encouraged us to look for more advanced, scalable solutions that were also personalised. We began transitioning towards machine learning (ML). This move was essential in overcoming the shortcomings of the rule-based system and in developing a more robust, adaptable categorisation engine.
Why is the problem so hard?
- Transactional data is inherently unstructured, messy, and varies across different banks.
- Ambiguities in merchant and category tags present unique challenges; for example, “Swiggy” and “Swiggy Instamart” have similar narration patterns but cater to different categories.
- Reliance on Merchant Category Codes (MCC) can lead to inaccurate categorisation.
- Differentiating between similar transactions requires using multiple signals, a task that rule-based systems struggle with significantly. Categorisation is not a one-size-fits-all approach; it's very subjective and personal for each user.
What did we do to solve it?
To address these challenges, we developed a machine-learning solution using a vector database and an embedding-based lookup. We go into further detail about our solution in the sections that follow.
Embeddings
Our systems communicate with your transactions through embeddings. In simpler terms, it's a numerical code that indicates the difference between your Swiggy and insurance purchases.
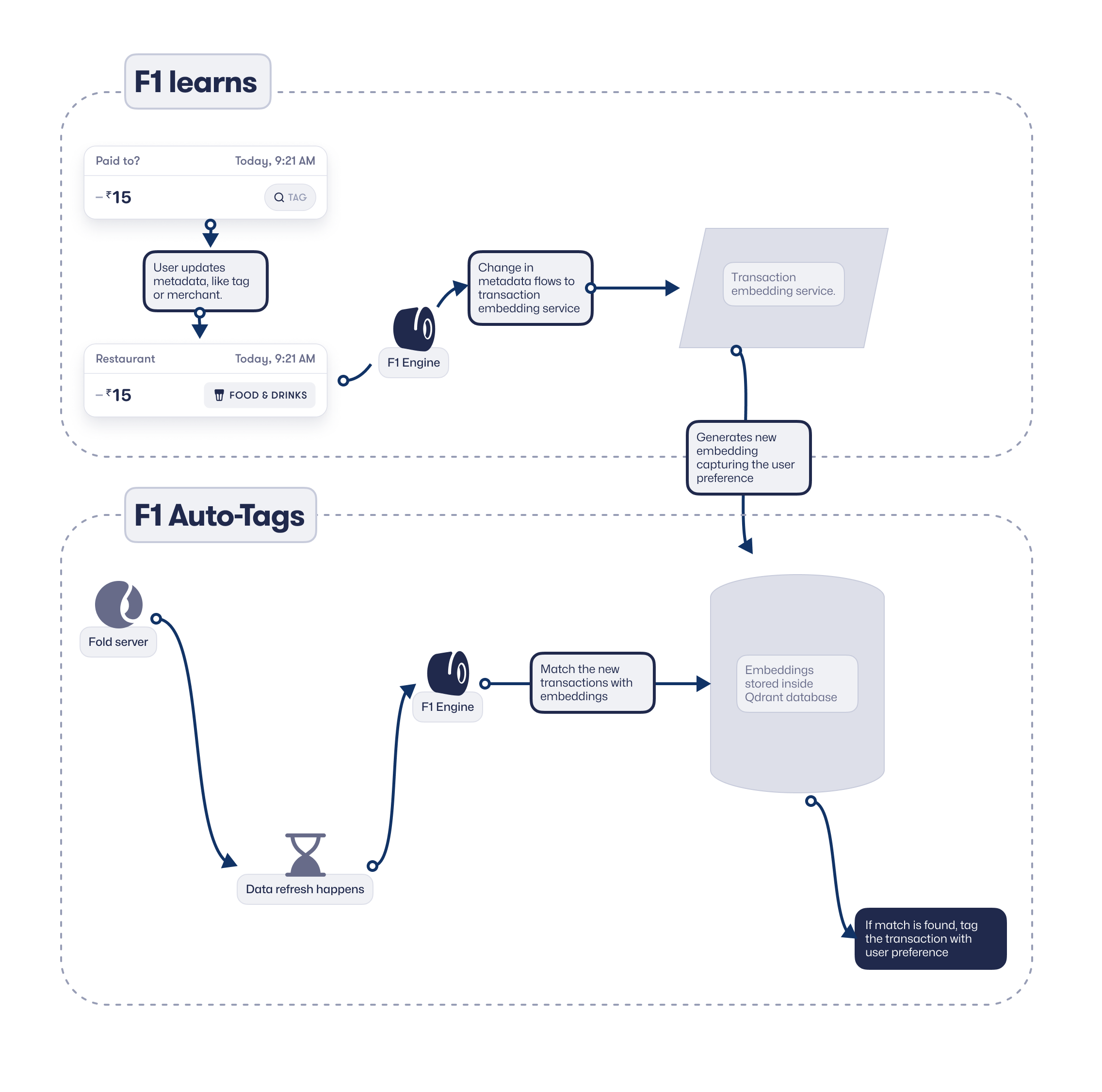
Figure illustrating a two-step process involving a learning and tagging system in F1.
The Role of Embeddings in F1
In our system, embeddings play a crucial role in natural language processing (NLP). They do more than just represent text; they capture the deeper semantic and syntactic meanings, helping our models understand the context and nuances of language.
- Contextual Importance: Embeddings consider the context around words, crucial for understanding language nuances and polysemy.
- Attention Mechanism: We utilize the Attention Mechanism, especially in Large Language Models, to enable the model to focus on relevant parts of the input. This results in a more nuanced and accurate understanding of the data.
Our system processes a corpus containing detailed semantic information about merchants or transaction categories. We use an open-source model to generate these embeddings, ensuring that similar transactions are grouped closely together in the embedding space.

Figure illustrating the embedding space of Transactional Entities.
Why did we choose Qdrant?
Qdrant was selected for its exceptional capabilities in pattern recognition within complex data sets:
- Optimized for Similarity Search: It's specifically designed for high-dimensional vector spaces, ideal for machine learning and AI applications.
- Efficient Storage: Qdrant uses an optimized format for storing high-dimensional vectors, ensuring efficient memory and disk space usage.
- Scalability: Given the vast amount of transactional data we handle, Qdrant's ability to manage large data volumes makes it an ideal choice.
Utilizing Transactions Embeddings
Learnings from manually tagged transactions are processed and stored as embeddings, capturing essential details like the amount, timestamp, and narration. These user-specific embeddings are then saved in the Qdrant database for future transaction tagging.
Implementing Top-k Matches
For a new transaction to be tagged, the F1 engine gets the top k matches from the past. A group of heuristics helps us figure out which match is the best in the group, so we can settle these matches. This includes standardising the merchant names ("Chai" vs. "Chai Shop"), and unifying transaction metadata across multiple results.
Controlling False-Positives
Machine learning models are never completely right by design. It may work perfectly in some cases but can also have significant false positives in others. We proactively try to add a verification step to get rid of patterns that are known to be ambiguous. These patterns are constantly updated to provide our users with a seamless categorisation experience.
What’s next?
We're just scratching the surface of what's possible with F1. Looking ahead, our focus will be on:
- Reducing manual Tagging effort: By integrating the tagging patterns of our user community, we aim to minimize the need for manual tagging, thereby making the categorisation process more efficient.
- Developing in-house Embedding models: Currently utilizing opensource models for word embeddings, we're shifting towards creating these in-house, specifically tailored to our unique requirements.
- Utilising Embedding Insights: We plan to use insights from embeddings to identify common tagging patterns. This will help F1 automatically categorise transactions that are frequently labelled the same way by many users, thereby increasing its effectiveness globally.
- Better accuracy and coverage: We are also developing a new category classifier [more on this in the next blog] which will significantly improve the accuracy and coverage.
Join Us
Building F1 has been one of the most exciting challenges we've faced at Fold. If you're interested in what we're building and want to help make personal finance easier for everyone, get in touch with us at [email protected].
If you’ve read this far here’s a little gift for you.