
One of the most essential features of Fold is its sophisticated transaction search system. We want our users to be able to easily find anything related to their transactions, no matter how complex their query may be. Our objective is to make the search experience as intuitive and robust as possible. Therefore, we have constructed a transaction search system that leverages the latest advancements in Natural Language Processing (NLP) to deliver the most pertinent results.
This blog provides insights into how our transaction search system has evolved over time.
The Genesis: ilike Matches
We started with a simple goal: to match, search, and return relevant transactions.
Initially, our system was built on the foundational principles of PostgreSQL, using the 'ilike' pattern-matching feature. This system functioned by performing partial matches on all transaction attributes and filtered out and returned the relevant results.
Consider this simple query: SELECT * FROM transactions WHERE merchant ILIKE '%Swiggy%';
The above SQL query scans the entire 'transactions' table, looks for the word 'Swiggy' in the merchant column, and returns any row where it finds a match, no matter where 'Swiggy' appears in the string.
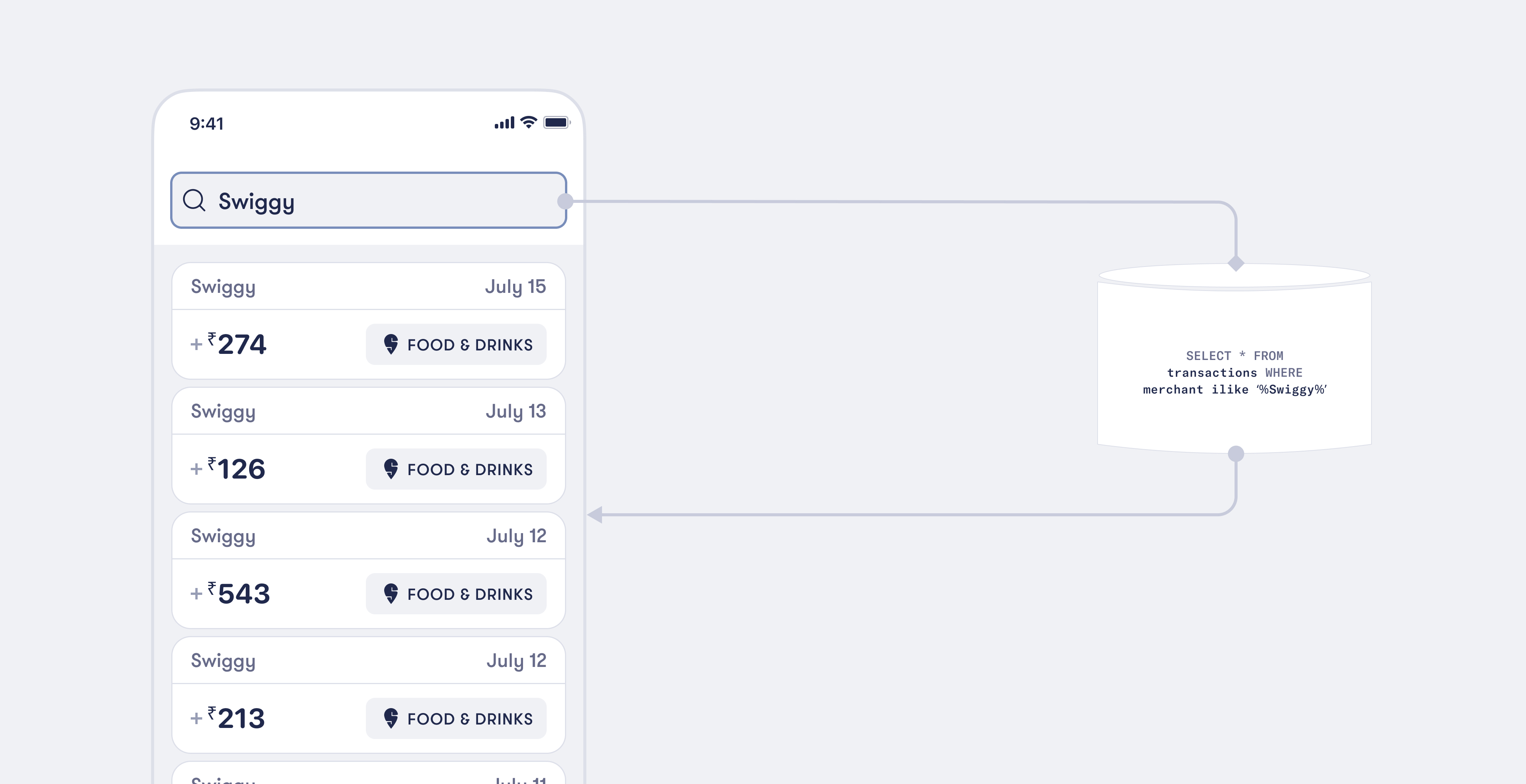
In practice, this approach facilitated an exhaustive search, retrieving any and all matches. However, we realized that while the system was effective for direct matches, it fell short when dealing with queries that required a higher level of precision.
Hence, we started looking for solutions that could not only match keywords but also comprehend the context of the search query.
This exploration led us to the realm of Natural Language Processing (NLP), enabling our system to evolve from a basic pattern-matching tool to an advanced search assistant.
Building the contextual layer
The next logical stride was to incorporate a layer that could extract the context from the search bar, dynamically build the query, and filter results based on this context. This is when we started exploring Natural Language Processing (NLP), and our search led us to RASA, a framework for developing the contextual layer.
We utilized RASA's capabilities to construct an intent and entity-based model, transforming our search system.
An intent represents the purpose or goal of a user's input, while an entity is a specific piece of information that the system extracts from the user's input. By training this model on common search patterns in our database, we enabled our system to accurately identify these entities and intents.
Consider this user input: "Show my transactions with Uber last month"
In this example, RASA enables our system to identify 'Uber' as an entity and 'Show my transactions' as the intent. The system swiftly understands that the user wants to see their Uber transactions from the previous month. This context-rich understanding allowed our dynamic query builder to create highly targeted queries, yielding precise and relevant data.
But we didn't stop there. By integrating the Duckling extractor, our system was also able to extract time-based entities. In the above example, 'last month' is recognized as a time entity, enabling the system to refine the results even further.
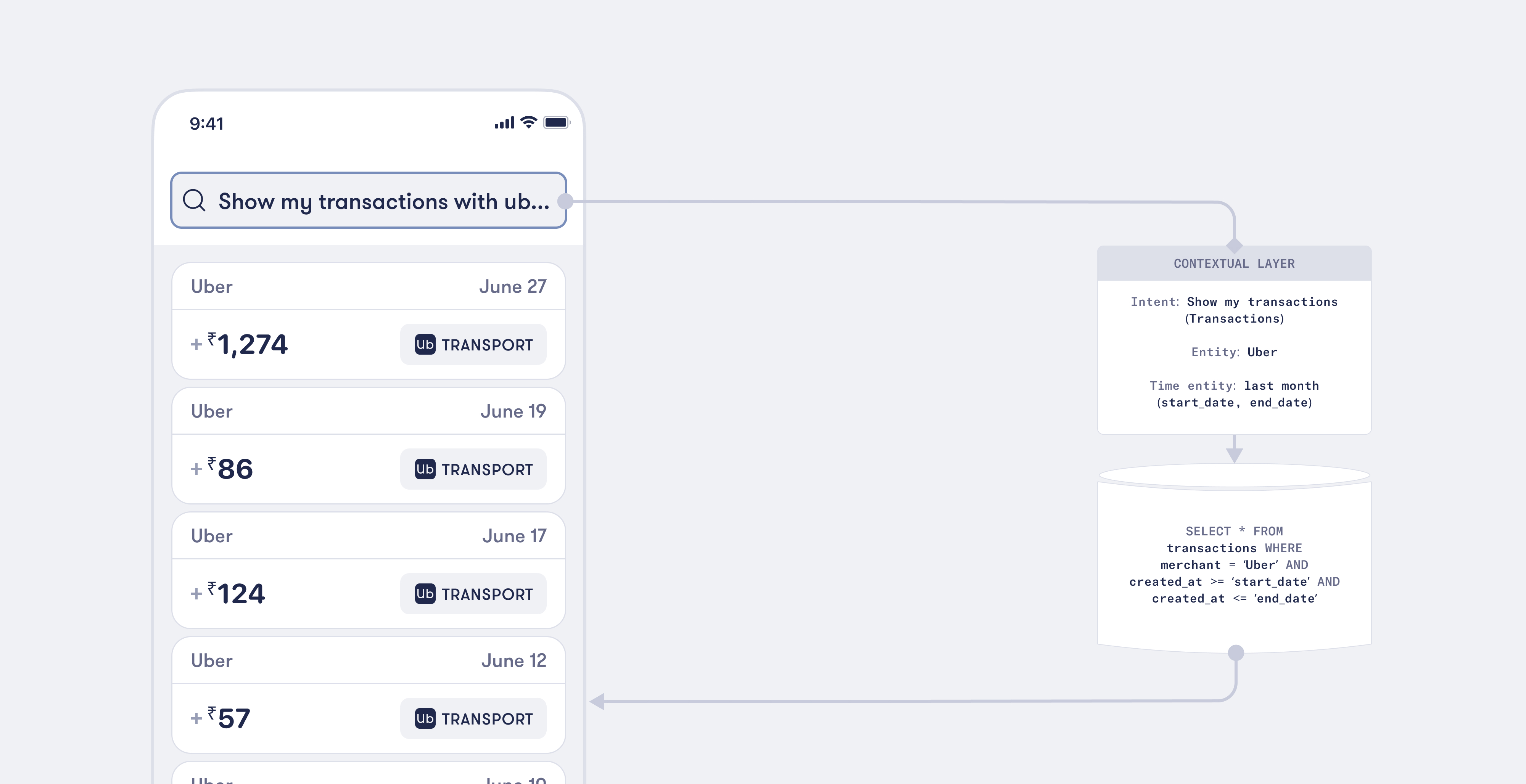
This shift from the 'ilike' matching system to intent and entity-based models resulted in a significant improvement. Our system went from matching keywords to understanding user intent and recognizing critical entities - a leap towards higher accuracy and relevant results.
Regular Training and Updates
We understood early that our system, like us, would need to be a constant learner, evolving with the data and adapting to new patterns. That's why we keep training our model continuously.
While our system is great at handling simple queries, it can struggle with complex ones like "Spent on food only on Swiggy" or "Spent on travel excluding Uber." These queries require extensive training to extract the appropriate intent. Spelling errors in merchant names or categories also add another layer of complexity.
The constant influx of new and unseen search patterns made it crucial for us to frequently update and train our model, necessitating rigorous monitoring. Additionally, we aimed to enhance the contextual understanding of our system, a feature that, if perfected, could dramatically improve the precision of search results.
Future Plans: Building the intelligence layer
Recently, we have been delving into open-source Large Language Models (LLMs) to further refine our transaction search system. LLMs are powerful tools that can grasp the intricacies of human language. By leveraging LLMs, we can make our system more efficient and accurate.
One of our goals is to replace the existing contextual layer with an intelligence layer. This would allow the search bar to understand user input more intelligently and return the most relevant results, regardless of the query's complexity or specificity.
We believe that by incorporating intelligence directly into the search bar, we can craft a seamless user experience. We look forward to the future of transaction search, and we are committed to making our system the best it can possibly be.
Join Us
Our journey towards building the best possible transaction search system is still underway. We are on the lookout for passionate Machine Learning engineers and researchers who are intrigued by solving complex problems in the fields of NLP and AI. If this appeals to you, please send an email to [email protected].